Overview of our two-stage fine-tuning strategy. We run prompt
$ 11.00 · 4.5 (561) · In stock


Instruction Fine-Tuning: Does Prompt Loss Matter?

MetaICL Learning to Learn In Context (NAACL 2022)_哔哩哔哩_bilibili
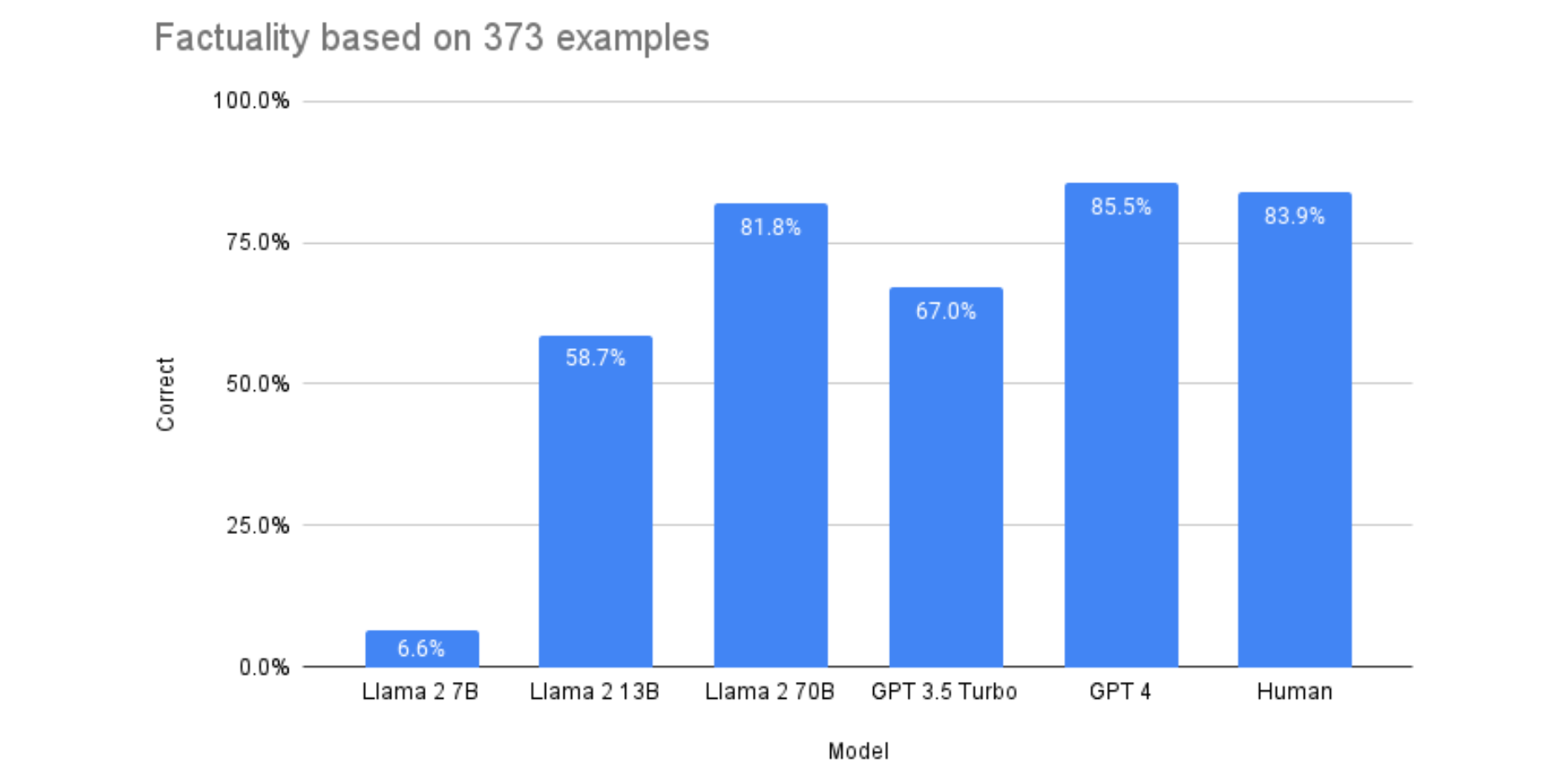
Llama 2 vs. GPT-4: Nearly As Accurate and 30X Cheaper

Overview of our two-stage fine-tuning strategy. We run prompt
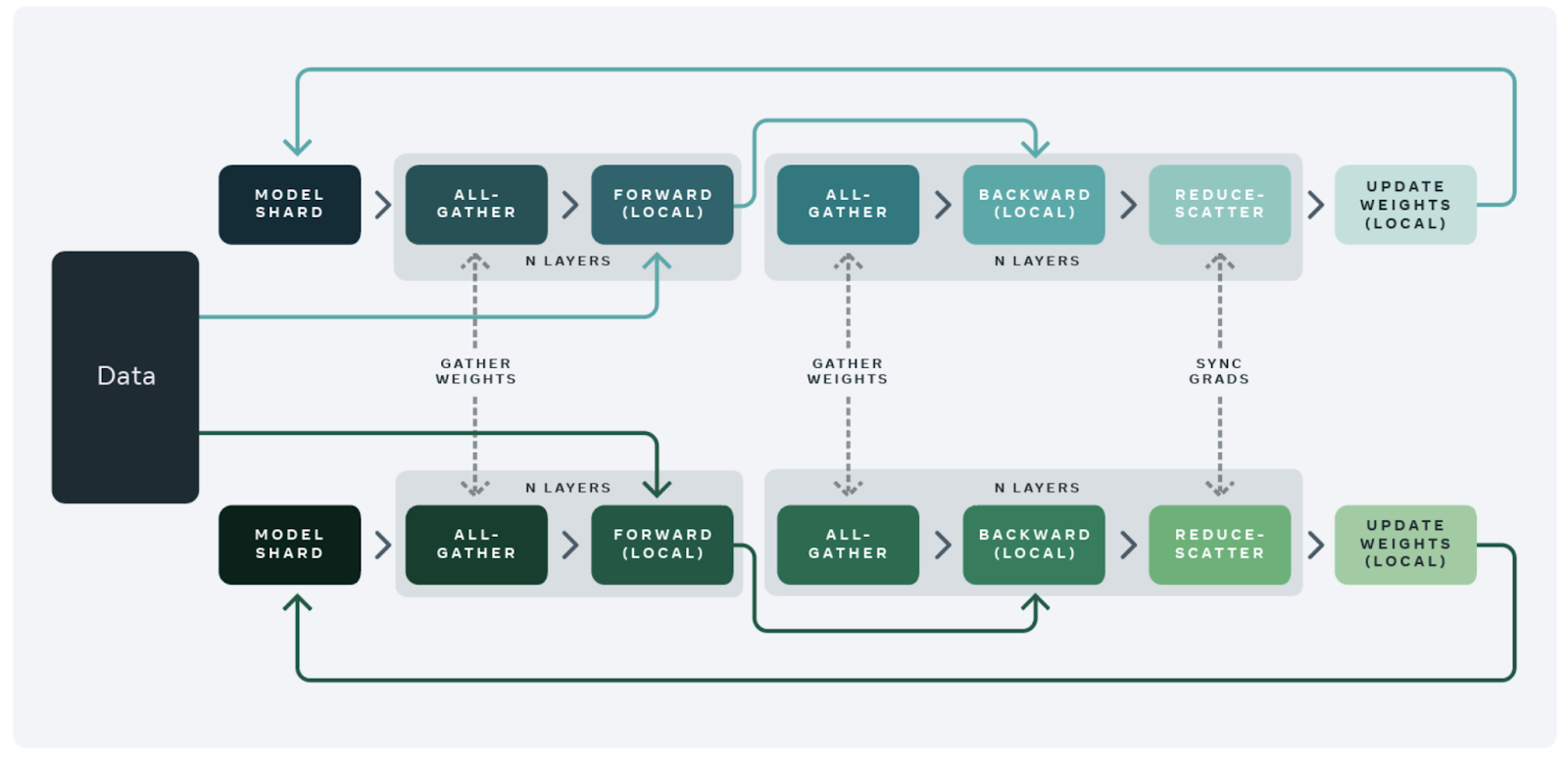
Fine Tuning vs. Prompt Engineering Large Language Models •

A step-by-step guide to competitive market analysis
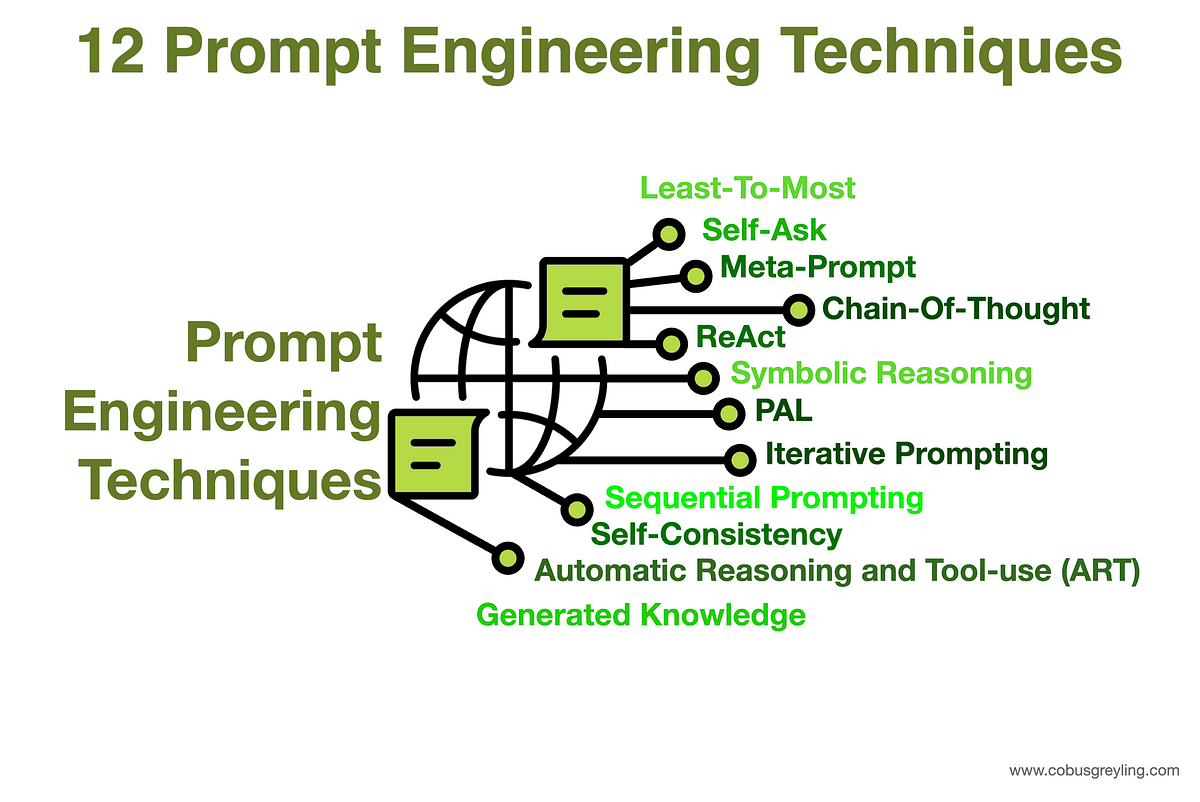
12 Prompt Engineering Techniques. Prompt Engineering can be
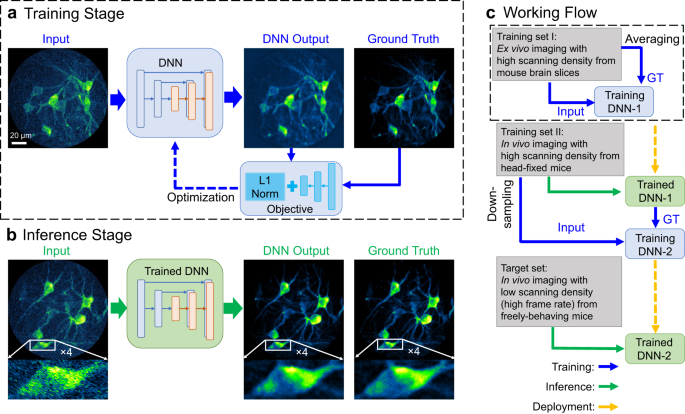
Deep-learning two-photon fiberscopy for video-rate brain imaging
Mistral 7B Tutorial: A Step-by-Step Guide to Using and Fine-Tuning

Inderjit S. Dhillon's research works University of Texas at Austin, TX (UT) and other places

Preserving In-Context Learning Alibility in Large Language Model Fine-tuning (Ar_哔哩哔哩_bilibili